class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.tok_emb = nn.Embedding(vocab_size, n_emb)
self.pos_emb = nn.Embedding(block_size, n_emb)
self.blocks = nn.Sequential(
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
)
self.lm_head = nn.Linear(n_emb, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
tok_emb = self.tok_emb(idx) # (B,T,E)
pos_emb = self.pos_emb(torch.arange(T, device=device)) # (T,E)
x = tok_emb + pos_emb
x = self.blocks(x)
logits = self.lm_head(x) # (B,T,C)
if targets == None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:,-block_size:]
logits, loss = self(idx_cond)
logits = logits[:, -1, :] # (B,C)
probs = F.softmax(logits, dim=-1) # (B,C)
idx_next = torch.multinomial(probs, num_samples=1) #(B,1)
idx = torch.cat((idx, idx_next), dim=1) #(B, T+1)
return idxnn.Module로부터 상속받아 SimpleModel class를 만든다. pytorch에서 모델을 만들 때는 반드시 nn.Module을 상속받아야 하고, contructor(init)과 forward 함수를 반드시 작성하여야 한다.
init
이 class의 생성자로 반드시 작성되어야 한다. tok_emb는 token embedding, pos_embedding은 positional embedding으로,
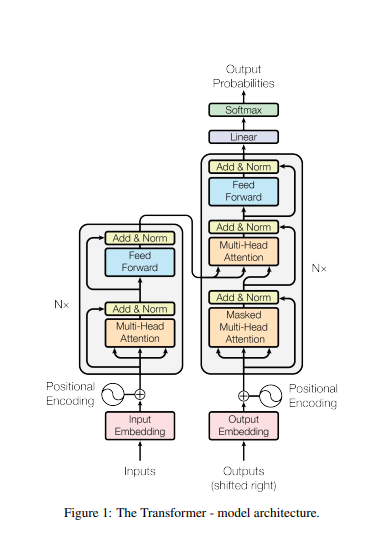
위 참조 그림에서 "Output Embedding"(분홍색 박스)에 해당하는 영역이 token embedding, token embedding 후에 적용되는 부분이(태극문양) Positional Embedding이다. Token Embedding과 Positional Embedding이 어떤 역할을 하는지는 Encoder 를 다룰 때 설명하였다. 여기서 Token embedding은 각 character를 숫자로 바꿔 주는 역할, positional embedding은 해당 character의 위치를 숫자로 바꿔 주는 역할을 한다.
Block은 참조 그림에서 우측 박스를 나타낸다. 이 과정을 Nx 번 반복해야 하는데, 우리는 이번 실습에서 3번만 반복할 것이다.
self.blocks = nn.Sequential(
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
Block(n_emb, n_head=4),
)self.lm_head = nn.Linear(n_emb, vocab_size)위 코드는 block을 빠져나온 결과값이 통과하게 되는 Linear Layer를 정의한 것이다. 이 Linear Layer를 통과하면, 그 결과값은 해당 문자가 (a일 확률, b일 확률, ...... )의 형태가 된다.
forward
forward 함수는 model이 계산을 했을 때 다음 결과를 반환하는 함수이다.
init에서 initialize한 token, positional embedding을 가지고 token embedding, positional embedding을 하여 각각의 결과를 tok_/pos_embedding에 저장한다. 이후 두 값을 합쳐서 다음 단계로 보낸다.
x = tok_emb + pos_emb
x = self.blocks(x)
logits = self.lm_head(x)앞서 init 함수에서 정의하였듯, x를 block으로 보내면 3번 반복하게 된다.
그리 하여 나온 값을 다시 Linear Layer에 통과시킨다.

위 그림을 보며 다시 한 번 설명해 보면, output embedding(token embedding) 값과 positional embedding의 값을 더하여 block으로 보내면 그것을 N(여기서는 N=3) 번 반복하고, 그 값을 다시 Linear Layer에 통과시키는 것이다.
Block
class Block(nn.Module):
def __init__(self, n_emb, n_head):
super().__init__()
head_size = n_emb // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedForward(n_emb)
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x.
Block을 정의한 class이다. x가 input으로 들어오면 그 값을 layer normalization하여 MultiHead Attention으로 보내고, 그 값을 다시 자기 자신(x)와 더한다. 이 과정이 Add&Norm이다. 계속 참조한 그림과는 순서가 약간 다른데, 이 부분은 Layer Normalization을 먼저 하는 것이 경험적으로 더 낫다는 데에서 기인한 차이라고 보면 된다.
우리의 모델에서는 cross attention 부분을 생략하기 때문에, 바로 Feed Forward Network로 넘어간다. 작동 논리는 MutliHead Attention의 경우와 같다. 다만 MultiHead Attention과 Feed Forward Network class가 다음과 같은 차이가 있을 뿐이다.
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
def forward(self, x):
return torch.cat([h(x) for h in self.heads], dim=-1)
class FeedForward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_emb, n_emb),
nn.ReLU()
)
def forward(self, x):
return self.net(x)
Head
Multi-Head attention의 이름에서도 알 수 있듯, Multi-Head attention에는 Head가 여러 개 필요하다.
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.k = nn.Linear(n_emb, head_size, bias=False)
self.q = nn.Linear(n_emb, head_size, bias=False)
self.v = nn.Linear(n_emb, head_size, bias=False)
def forward(self, x):
B, T, C = x.shape
k = self.k(x) #
q = self.q(x)
v = self.v(x)
out = F.scaled_dot_product_attention(q, k, v, is_causal=True)
return out
Head는 위와 같이 정의되는데, input을 Linear Layer에 통과시킨 다음에 scaled dot product 연산한 값을 반환한다.
'경제학코딩 2023' 카테고리의 다른 글
| [Decoder Generator] (1) | 2023.12.17 |
|---|---|
| [Decoder Data Step] (1) | 2023.12.17 |
| [Attention Mask] (1) | 2023.12.17 |
| [Scaled dot product] (1) | 2023.12.17 |
| [Encoder Only Model with imdb] (0) | 2023.12.17 |



